 I don’t know exactly what started my interest in Machine Learning and AI in general, but it’s a topic that I monitor for a long time now. The vast amount of possibilities sparkle my creativity and I love to experiment with it. Especially now services from Google and Azure made it so simple to build cool stuff with it. But I am also interested in how things work, that’s why I love to dive deeper into the subject. And when I gain some knowledge, it’s always fun to share that knowledge with others. This blog is about an introduction to the topic Machine Learning I gave at my work. It was a small presentation just covering some of the basics, but just enough to get started with it.
I don’t know exactly what started my interest in Machine Learning and AI in general, but it’s a topic that I monitor for a long time now. The vast amount of possibilities sparkle my creativity and I love to experiment with it. Especially now services from Google and Azure made it so simple to build cool stuff with it. But I am also interested in how things work, that’s why I love to dive deeper into the subject. And when I gain some knowledge, it’s always fun to share that knowledge with others. This blog is about an introduction to the topic Machine Learning I gave at my work. It was a small presentation just covering some of the basics, but just enough to get started with it.
What is machine learning?
Probably you have heard about terms like Artificial Intelligence (AI) and Machine Learning interchangeably. There is a difference. Artificial Intelligence comprehends all technology that involves making machines more intelligent. Machine learning is just a subset of AI. It’s one way of accomplishing this. In this blog I will dive deeper into machine learning itself. The subset is big enough to write multiple books about it. I will keep it to the basics for now.
But what is Machine learning now exactly? Let me quote a person named Arthur Samual, because he summarizes what machine learning exactly is very beautiful in just one sentence:
A field of study that gives computers the ability to learn without being explicitly programmed
~ Arthur Samuel
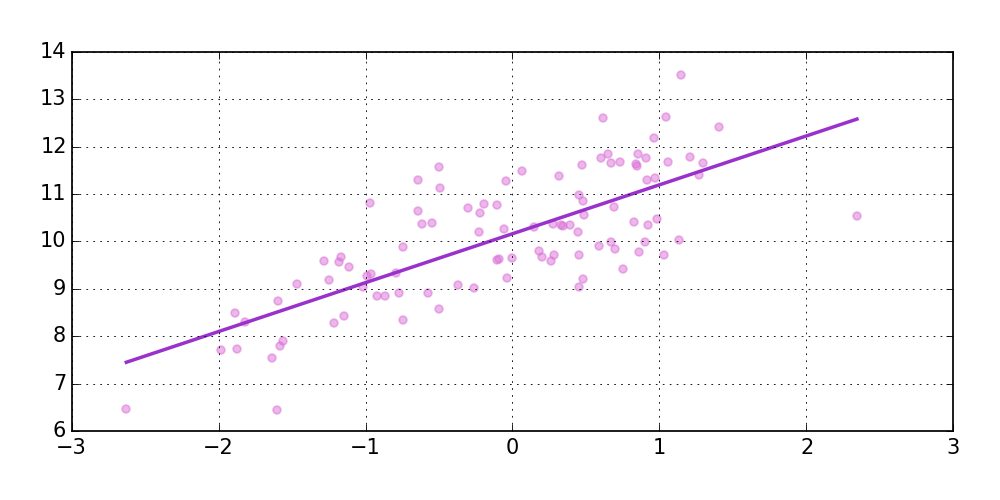
So what does this mean? Let me clarify it with an example, because who doesn’t like examples, right? Imagine you have a dataset with data about houses such as, surface, location, whether it has a garden or not, etc. This dataset is labeled, meaning, you also know the market value of these houses. Now, as a developer, you are asked to write a program that is capable of determining the market value of any other house when you give the program as input the features as mentioned above. You will have to analyze the dataset and find relations between the various features and the market value. For example, you may notice that a large surface area has a positive influence on the market value, but that, depending on the location of the house, the value is also influenced. After identifying all these relations you have to write the logic. This is not an easy job. Certainly not if the datasets become more complicated, with more variables. Machine learning tries to solve this problem. Machine learning learns the relations from the dataset and writes the logic for you. The logic is not fixed, but rewritten every time when new relations are discovered or previous relations cannot be explained anymore.
At the beginning of this paragraph I already briefly mentioned a person named Arthur Samuel. He is not just a random person, but he is actually a pioneer in the field of Machine Learning. He wrote the first self-thinking program. A checkers program in which it was possible to play against a computer. That was quite a challenge at the time. The computers were not yet so powerful, so Arthur Samuel had to write an algorithm that was also very efficient with the available resources. What I am trying to make clear here is that Machine Learning is certainly not recent technology or invention. Research has been done for decades, started in the field of mathematics, finding algorithms. Now that computers are powerful enough to actually emulate neural networks, you are hearing more and more about Machine Learning. Especially because Machine Learning has so much potential and already shows amazing results.
Machine Learning can be categorized by how you try to teach a machine something. In short there are three main categories:
- Supervised learning
- Unsupported learning
- Reinforcement learning
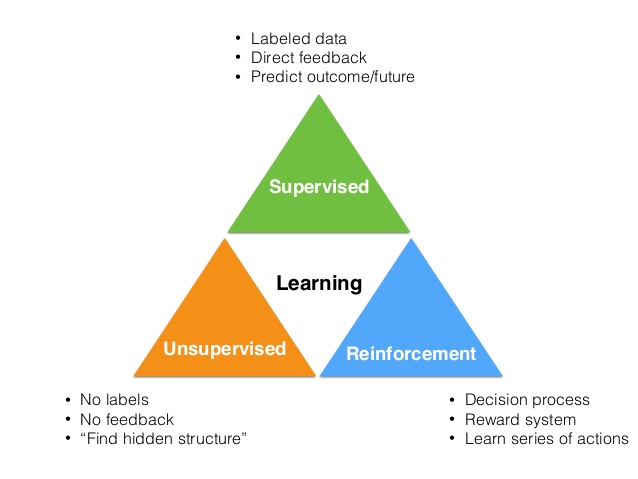
Supervised learning
In supervised learning you have a labeled dataset. The model is trained on this labeled dataset. Meaning you do not only have a dataset with the properties of a house but also the market value of that specific house. In general a machine learning algorithm that is optimized for supervised learning searches for the best mapping function. For example, let’s say you have the following dataset:
<table example>
The rows in this dataset are called observations. The properties of the house do we call attributes and the market value, is the label or feature. Most of the attributes are numeric. Those who are not are called categorical values. They need to be converted to numerical values before feeding this dataset to a machine learning algoritme. Basically there are two types of supervised learning, classification and regression. A simple example of classification is a algoritme that classifies mail as spam or not spam. The observation is an email with certain attributes and the algorithm classifies it as spam or not spam. You train such algorithm by labeled data. For example, you receive an email and you tell Google that it’s spam. So you label the observation making it supervised learning. Supervised learning tries to categorize the observations. If these categories are discrete, meaning there is only a limited set of categories we call it classification. So an algorithm determining if a mail is spam or not spam is a classification example. If the categories are continues, meaning there are unlimited categories, like for example the market value of a house, then we call it regression.
Unsupervised learning
What if we have observations but no labels. Or the labels cannot be trusted. Then it’s better to train using unsupervised learning. Unsupervised learning doesn’t need any prior training, it’s able to process more complex tasks but it’s also more unpredictable. Clustering and dimensionality reduction are to examples of unsupervised learning. Let’s say we have a basket of fruit and use unsupervised learning to learn identifying this fruit. Clustering means that the algoritme searches for relations and similarities between the fruit. Ideally we hope the end up with clusters of apples, bananas etc. So when we show the algoritme a type of fruit it will tell us to which cluster it belongs and we can label it as an apple. But these algoritmes don’t know what apples and bananas are. So the fruit will be clustered by size, by color, by shape and maybe taste. It’s even possible that the algoritme finds a similarity that we have yet thought about. This makes it more unpredictable because it’s harder to understand why your algoritme puts an apple in the same cluster as a mandarine. Maybe it’s because of the shape or size, maybe because they grow both on a tree. So using an unsupervised learning algoritme to identify fruit can create very unpredictable results.
Reinforcement learning
With this type of learning there not even a dataset. It’s used for example for self-driving cars. The environment in which these cars drive is so dynamic, consists of so many variables, that observations do not help much learning to deal with such environments. Take for example yourself trying to learn playing tennis. You can’t learn playing tennis just by reading books or watching other people. You have to do it yourself, experience it, to learn it well. In reinforcement learning you have an agent, the self-driving car for example, and an environment, the road with all it’s traffic. The self-driving car uses sensors to detect the ‘state’ of the environment. Then it takes an action, for example accelerate and receives a reward for this. Based on the reward and the new state of the environment it takes a new action and ‘learns’ which action leads to positive rewards and which not. In this example the reward could be, stay on the road, make no accidents and get closer to your destination. As long as the rewards are positive it keeps accelerating. As soon as one of the sensors detects an obstruction, which leads to a negative reward, it changes it’s action until the reward get’s positive again. This is a very basic explanation but this is how it approximately works.
Neural networks
Until now I told you what machine learning is and explained the basic machine learning categories. But how can a algoritme learn something? How does the learning part work? I will try to explain that now using neural networks. I will use a neural network because it appeals most to the imagination because it works a bit like our brains.
There are numerous algorithms and they all ‘learn’ in their own way. Neural networks is very advance topic. Therefore, let me start with a very basic neural network, the perceptron.
A perceptron is binary neuron, the most simple neuron you can think of. The perceptron has 3 inputs and 1 output. The output is the sum of the weighted inputs compared to a threshold value and is therefore 0 or 1:
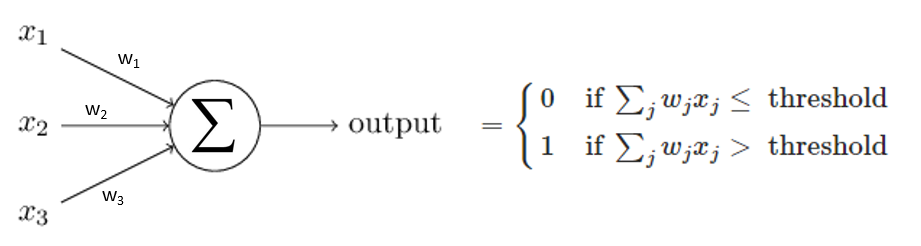
This is a decision node. The weights are w1 to w3 and these determine how important an input (x1 to x3) is for making the final decision. Let me explain this with an example:
Let’s ask this decision node whether you are going to a festival or not. The inputs are:
x1: Your friends are going (Yes / No)
x2: The weather is good (Yes / No)
x3: A good public transport connection is available (Yes / No)
Let’s say when your friends are joining (x1 = 1) you want to go to the festival even if the weather is bad or no public transportation is available. Then this input is the most important and w1 (weight) will be the largest. The output is compared with a threshold value, also called bias. With this you can still play ‘how much you like’ to go to the festival. After all, with a low threshold value, the node takes the decision to go rather than a high one. Notice how important the weights and bias are for making a certain decision. This is important to know in order to understand how such a network can learn something.
The weighted sum of inputs is compared with a threshold value. In other words, the result of this sum is mapped to a step function. The function responsible for the mapping is also called the activation function. In this introduction I will limit myself to two of the most simple activation functions:
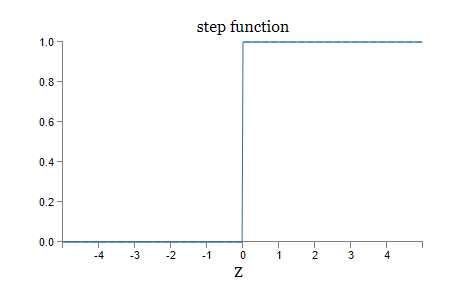
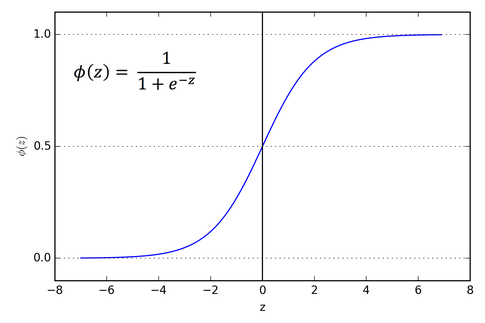
The step function is actually too simple. By a small change of the weights the output can suddenly jump from 0 to 1. This inconstant behavior makes it difficult to learn the network something. Imagine trying to teach someone something who’s opinion changes 180 degrees as soon as you change a small detail of your story. It is difficult to understand what you have to do so that this person agrees with it. The same applies to neural networks. That is why a Sigmoid activation function is much more convenient. In that case the sum is mapped to a number between 0 and 1. The inputs can now have any value between 0 and 1. With a small change of the weights, the output now also changes slightly. This is a useful feature for learning a network.
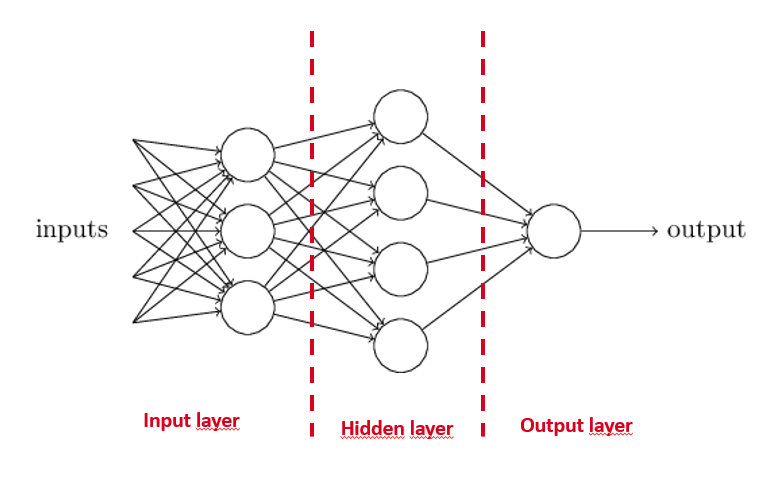
Here you can see an example of a simple neural network. If there is more then 1 hidden layer it’s called Deep Learning. Each hidden layer then adds an extra abstraction layer for making a decision. But how can such a network learn something? Simply said you first choose random weights for all inputs. Then you need a labeled dataset. You offer that dataset to the network. The data propagates through the network and gives an output. This output differs from the input. We call the mean squared error (MSE) of this difference the cost. You want to make the cost as low as possible. You do this by adjusting the weights in the network. The weights are the tuning parameters of the neural network. By tuning them you create certain behavior in the neural network. But the question now is how to change these weights? Should they all be changed and should they be higher or lower and how much higher and how much lower should the weight be?
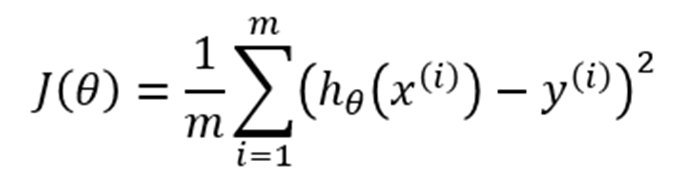
The above function is called a cost function. Simply said you take the square of the difference between the real output and the expected output. Then you sum this over all ‘m’ training examples and divide it by the amount of training examples. The reason you take the square from the difference is that it shouldn’t matter whether the difference is positive or negative. It’s still an error. So at the end you are looking for the the value of θ (weight) that minimizes J.
In mathematics you probably learned that finding the minimum of a function can be done by finding the derivative with respect to a control variable, here its weight (θ). Loosely translated the derivative is a measurement for the amount of change. The steeper the derivative is the more a variable changes. So finding the weights (θ) that minimizes the cost function can be done by taking the derivative of this cost function with respect to it’s weights:
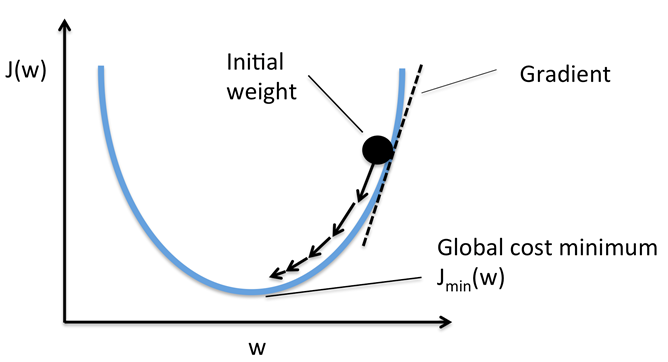
In the graph above I simplified the cost function to make it easier to explain how it works. It’s a one dimensional function only depending on a single weight (w). The purpose is finding the weight (w) that minimizes J(w). Sorry for the switch from θ to w. I borrowed this graph from the internet because I was to lazy to draw one myself ;-).
Looking at the graph you can clearly see which value ‘w’ minimizes the cost function. Now take a look at the gradient, which can be found by taking the derivative of the cost function. If the gradient is positive, like in the graph above, the value of the weight is to large and needs to be smaller. When it’s negative, the line sits on the other side of the graph, then ‘w’ is too small and needs to be larger. Depending on how steep the gradient line is tells you if the weights need to be a bit smaller or much smaller. In the graph above the steeper the gradient the further up the gradient is and thus further away from the minimum value. In neural networks finding the weights like this is called backpropagation because you are propagating back and forward through the network ‘m’ training sessions until the error goes to zero. After that all weights are set and the network has learned from the labeled dataset.
Interested in more information look at these great sites:
- http://mccormickml.com/2014/03/04/gradient-descent-derivation/
- https://medium.com/towards-data-science/types-of-optimization-algorithms-used-in-neural-networks-and-ways-to-optimize-gradient-95ae5d39529f
Let’s create your own neural network!
You don’t need to be a mathematics genius to start playing around with Machine Learning. Some very nice frameworks exist that help you get up and running quickly. Some of them are:
- TensorFlow
Gives you the opportunity to build your own Machine Learning algorithm using simple building blocks - Scikit learn
Pyhton framework with out of the box algorithms for classification, regression, clustering etc.
If you are a PHP developer there is also a framework called PHP-ML that makes it very easy to create your own neural network in PHP. The main purpose of this PHP framework is to get a better understanding about machine learning algorithms. If you really want to use them on real world cases I would recommend using Scikit learn and writing it in python.
And if all of the above is even to complex for now you can always use machine learning services on:
Practical concerns
Before you start creating or teaching your own first Machine Learning algoritme let’s talk about some practical things first. Understand that supervised learning is expensive. Getting a label dataset either takes a lot of time or costs a lot to gather. Let’s say you want to create an algoritme to detect cancer from CT scans. You need a huge labeled dataset of CT scans to make this work. And therefor you need doctors to look into al these CT scans and identify which contain cancer and which not. Then you need another group of doctors to verify these outcomes. You can imagine that they probably won’t do this for free.
Some costs can be reduced by doing some pre-training with public available free labeled datasets. For example when you want to train your model to identify a dog breed you can pre-train it with public available datasets to make it able to distinguish between what is an animal and what not. Then the labeled dataset you need to train it identifying the dog breed can be much smaller. Public available free datasets can be found in so called Model Zoo’s. A model zoo is a website containing models trained by companies, scientists etc that can be used for free for further training. Here is a list of some model zoo’s:
- https://github.com/BVLC/caffe/wiki/Model-Zoo
- https://github.com/fchollet/deep-learning-models
- http://mxnet.io/model_zoo/
- http://www.image-net.org/search?q=tree
Another way to get fairly cheap a labeled dataset is creating your own crawlers. Be aware that datasets gather in this way are noisy datasets. Meaning the labels can be wrong. But noisy datasets can by very helpful in pre-training a model.
Another practical problem you will notice when you start working with machine learning is that most algoritme expect a balanced datasets. In the case of detecting a dog breed chances are that you will find more data about certain popular dog breeds compared to less popular ones. Training your model with such unbalanced dataset means it will get very well in detecting certain dog breeds but not as good in detecting others. To counteract this effect you can use up/down sampling on your dataset.
Also be ware that most algorithm think that all errors are of equal importance. But that is not generally true. For example you can imagine that detecting that somebody has disease X and this is wrong, is a less significant error then, identifying somebody doesn’t have disease X but he actually has it. Especially when this algorithm is used by your doctor.
Last but not least trained models become very easy a blackbox. A simple neural network can already have 100 million parameters making it therefore very hard to understand why it took certain decisions. This can lead to unwanted and sometimes embarrassing decisions like what happened with google image labeling algorithm some years ago:
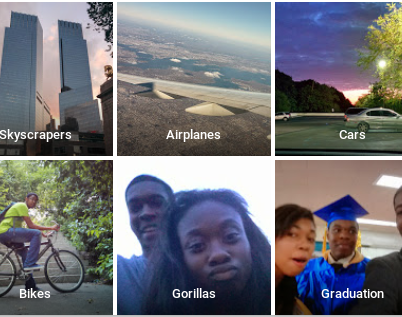
Can you see what mistake was made by this algorithm?
There are some tools available to visualize decision trees of neural networks like http://mldemos.epfl.ch/ but most work far from perfect.
I hope this doesn’t scare you getting familiar with Machine Learning. Just be ware of the above concerns and I believe you will see soon enough see how much potential it has. I really love experimenting with it. Soon I will add a blog about creating an artificial intelligent chatbot to your website that can learn from your visitors input using DialogFlow and Botman. Just be careful if you are going to do this yourself that you do not make the same mistakes as Microsoft did with their chatbot Tay ;-).