When I First heard about the Entity Framework I thought there was only one correct way of implementing it and that is using the Code First approach. Now I am not that sure anymore. In this article I will explain the various approaches and their advantages and disadvantages.
Model First
This approach can be a bit confusing to developers who are not really familiar yet with EF and are used to the MVC structure. By Model is meant a real model, not a model like the one you have in MVC where the model is coded. So the Model First approach means we create a diagram that will be automatically converted to a coded model. This in contradiction to the Code First approach where you create the Model in the code and there is no such thing as a diagram model.
In the Model First approach you start by creating a model like in the figure below in the Visual Studio Model Designer.
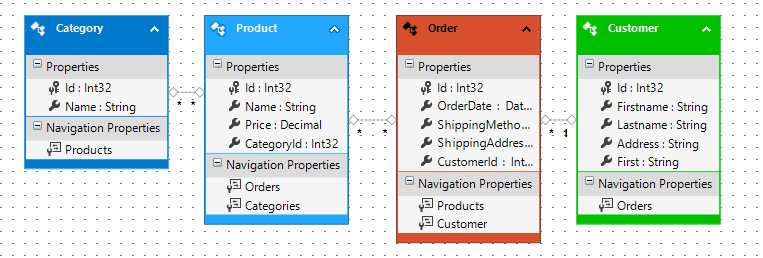
Example of a Model created in the Visual Studio Model Designer
Start by right-clicking on your project and choose Add->New Item and then choose ADO.NET Entity Data Model.
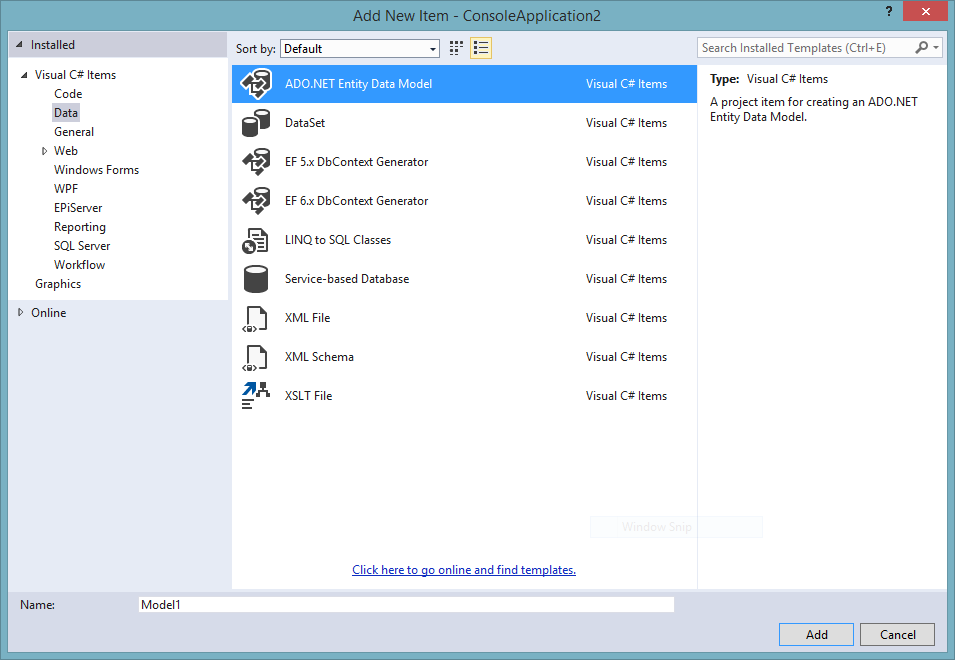
Add New Item dialog
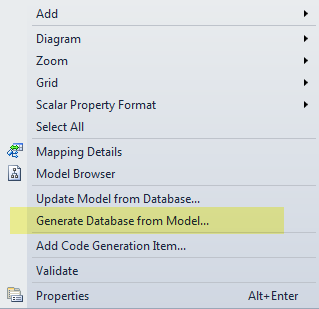 This will open a designer window. Next create your model by adding Entities, Associations and Entity properties until your model is a good representation of how your database should look like. Lets say your model looks like the model above. What we need to do now is apply this model to a database by right-clicking in the editor and choose Generate Database from Model…
This will open a designer window. Next create your model by adding Entities, Associations and Entity properties until your model is a good representation of how your database should look like. Lets say your model looks like the model above. What we need to do now is apply this model to a database by right-clicking in the editor and choose Generate Database from Model…
Follow the instructions on the screen. If you follow all steps then Visual Studio will create a database for you and add a connectionstring to your app.config. Visual Studio will also generate a SQL file. This DDL file contains all instructions required to create the necessary tables, columns and relations in your database. It is not yet executed so open the file, right-click on it and choose Execute from the context menu to apply the changes to the database.
That’s it. You database is now in sync with your model. You can validate this by right-clicking in your diagram and choose Validate.
Lets mess around
Now we get to the fun part. We will look at different scenarios and see how our code and model behave in such situations. The sample code I used for testing looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
using System; using System.Linq; namespace ConsoleApplication2 { class Program { static void Main(string[] args) { using (var db = new Model1Container1()) { var results = db.Customers.Where(x => x.Id != 0); foreach (var result in results) { Console.WriteLine(result.Firstname); } } Console.ReadLine(); } } } |
This application will just list all customers in the database. Nothing else for now.
Change the name of column in the database
Lets say we change the column name ‘Firstname’ to ‘First’ in the database. If we run our code now we get an exception of the type EntityCommandCompilationException. This should be a hint that there is something wrong with our model. So lets open our model (diagram) and choose Validate. Notice that validation is successful! That is because our model is not yet aware of any database changes. So we need to make it aware of changes first by right-click in the diagram and choose Update Model from Database. Just click Finish in the window that opens and validate it again. Now you will see an error like this:
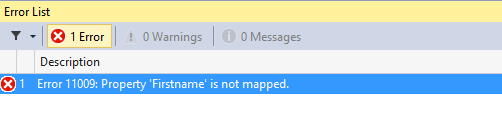
Right-click on the Customers model in the diagram to open the Mapping Details of the table Customers. Notice here that firstname is mapped to a non-existing column called firstname. Remember we renamed it to ‘First’. Correct the mapping and validate the model again. Now everything is fine again. Re-compile your project and run it to verify its working again.
Add a new column in the database
The webshop wants to store the age of every customers for some creepy reason. So we need an extra column in the database called ‘Age’. We can of course do this from our model but we do that later. If we run our application now everything still works. But obviously Age is not yet available and trying to retrieve the Age will result in an error.
Goto your model diagram, choose Update Model from Database and click finish. Save your model and run your application again. Notice that you can now retrieve the age of your customers.
Create a new table in your database and associate it with an existing one using the model designer
Lets create a location table and remove the fields ShippingAddress and Address from these tables because they are no longer needed. Do all of this from the database. After we updated the database lets go back to the visual studio model designer and choose Update Model from Database and remember to select your new table before clicking Finish. Validation will now throw two errors. ShippingAddress and Address is not mapped. Remove both of them from your model. Validate again and everything is fine now. Next associate customer with location and also order with location using a Many-to-One relationship. Last thing we need to do now is update our database from our model. So choose Generate Database from Model which will give you a new SQL script. Execute it and your database is in sync again with your model. Be carefull this will always result in data loss because tables are dropped first!
Advantages and Disadvantages
Advantages
- You can use a visual designer to create a database scheme
- Your model (diagram) can be easily updated when you make changes in the database. No data loss
Disadvantages
- When you change the model and generate SQL to sync the database then this will always lead to data loss except when you modify the script manually.
Database First
We have seen the Model First approach now and we know its advantages and disadvantages. We saw it was really easy to change the database and update the model without losing any data. The other way around always resulted in data loss or we needed to manually adjust the update SQL code. So the Database First approach seems to feel like the most logical way to work but what are the advantages and disadvantages of this approach? The database first approach means that you have already a database and you create a model from an existing database. Let’s use the project from above (Model First) and delete the model. Now right-click on your project and choose Add -> new item -> ADO.NET Entity Data Model and choose EF Designer from database.
Database First approach
Notice that you will end up with precisely the same model as you had in the Model First approach as expected. Only some class names can be different. From this point the Database First approach doesn’t differ at all from the Model First. The biggest difference is that we make only changes in the database and not in the model. But we saw already that this was also possible in the Model First approach.
Advantages and Disadvantages
Advantages
- You can use an existing database and create your tables and associations in there.
- Easy to avoid data loss on changes because you work from the database
Disadvantages
- Creating associations, foreign keys, constraints etc from the database can be more difficult.
- Not easy to sync database changes. Let’s say you change your database on your local machine then you need external tools to sync your changes with a remote database. This can be a major disadvantage.
Code First
We have seen the Model and Database First approach now and we know its advantages and disadvantages. I already spoke about the Code First approach in my blog ‘Introduction to the Entity Framework 6‘. Lets create the same models and dbcontext and start playing around.
First create a file called Models.cs
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
using System; using System.Collections.Generic; namespace ConsoleApplication2 { using System.Data.Entity; public class Order { public int OrderId { get; set; } public string Name { get; set; } public string Email { get; set; } public DateTime OrderDateTime { get; set; } public double TotalValue { get; set; } public virtual List<Product> Products { get; set; } } public class Product { public int ProductId { get; set; } public int ProductPageId { get; set; } public int Amount { get; set; } public double CurrentPrice { get; set; } public int OrderId { get; set; } public virtual Order Order { get; set; } } public class OrderContext : DbContext { public DbSet<Order> Orders { get; set; } public DbSet<Product> Products { get; set; } } } |
And use this code to test your database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
using System; using System.Linq; namespace ConsoleApplication2 { class Program { static void Main(string[] args) { using (var db = new OrderContext()) { var results = db.Orders.Where(x => x.OrderId != 0); foreach (var result in results) { Console.WriteLine(result.Name); } } Console.ReadLine(); } } } |
Next lets add a connectionstring to our App.config:
|
1 2 3 |
<connectionStrings> <add name="OrderContext" connectionString="Data Source=127.0.0.1;Initial Catalog=CodeFirst;Persist Security Info=True;User ID=sa;Password=*****" providerName="System.Data.SqlClient" /> </connectionStrings> |
Now lets create our database from our code model. Open Package Manager Consoleand type in these commands:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
PM> Enable-Migrations Checking if the context targets an existing database... Code First Migrations enabled for project ConsoleApplication2. PM> Add-Migration cmdlet Add-Migration at command pipeline position 1 Supply values for the following parameters: Name: Initial Scaffolding migration 'Initial'. The Designer Code for this migration file includes a snapshot of your current Code First model. This snapshot is used to calculate the changes to your model when you scaffold the next migration. If you make additional changes to your model that you want to include in this migration, then you can re-scaffold it by running 'Add-Migration Initial' again. PM> Update-Database Specify the '-Verbose' flag to view the SQL statements being applied to the target database. Applying explicit migrations: [201501071331147_Initial]. Applying explicit migration: 201501071331147_Initial. Running Seed method. |
That’s it. Our Code First is now working. Let’s add some data to the database and start messing around.
Lets mess around now
When using the Code First approach there is no way to sync changes from the database back into your model. So we limit us by updating the model and check what effect it has on our data.
Adding a new column to an empty table
I only added some orders in the database. No products yet. So you would think adding an extra column shouldn’t be that hard. Adding an column using the Code First approach means adding a property to the class Product. Let’s add a boolean property SoldOut. Next open the Package Manager Console and do:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
PM> Add-Migration cmdlet Add-Migration at command pipeline position 1 Supply values for the following parameters: Name: Column added to Product Scaffolding migration 'Column added to Product'. The Designer Code for this migration file includes a snapshot of your current Code First model. This snapshot is used to calculate the changes to your model when you scaffold the next migration. If you make additional changes to your model that you want to include in this migration, then you can re-scaffold it by running 'Add-Migration Column added to Product' again. PM> Update-Database Specify the '-Verbose' flag to view the SQL statements being applied to the target database. Applying explicit migrations: [201501071341500_Column added to Product]. Applying explicit migration: 201501071341500_Column added to Product. Running Seed method. |
Check the database and you will see the new column. But even better there is no data loss!!
Adding a column to a table with data
Lets do the same thing but now with a table that contains data. Again we see a new column and no data loss!!
Renaming a column and removing a column
Both work also nicely without losing any data.
Creating a new table and associate it to a table with data
I created a customer table and associated the customer with an order.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public class Order { ... public int CustomerId { get; set; } ... } public class Customer { public int CustomerId { get; set; } public string Name { get; set; } public virtual List<Order> Orders { get; set; } } public class OrderContext : DbContext { ... public DbSet<Customer> Customers { get; set; } } |
Next I run in the Package Manager Console the commands Add-Migration and Update-Database. Now the command Update-Database failed! The error was mumbling something about a foreign-key constraint. It could not create the association because there was data in the table Orders. So this action will lead to data loss but that was to be expected because we also need to empty the table when we want to do this in the database.
Lets delete some columns and tables and see if our Migrations can get our DB back in sync
Go to your database and delete the table Products. When your database version is newer then your model there is no way to get both back in sync anymore without data loss! You have to delete all tables from your database and run Update-Database again to get it back in sync. So remember to do all you database changes in your code!
Advantages and Disadvantages
Advantages
- Supports database migrations which make it very easy to keep various databases in sync
- Small model changes will not lead to any data loss
- You have more customization options and more control
Disadvantages
- It’s harder to maintain a database then using a visual design tool
- Knowledge of C# is required to create databases
Conclusion
It definitely depends on your situation which approach is most suitable for your project but after messing around with all three approaches I still prefer the Code First method. Why? I got a couple of reasons for it:
- Code First support database migrations
- Small changes to your code doesn’t lead to data loss. This also applies for database first approach ofcourse.
- Much simpler to keep databases in sync between developers and different versions of your application. For example if you are working in a feature branch then the migrations are also saved in this feature branch. So other developers will not see your new column. Of course this has a downside as well, later on you can have really nasty database scheme conflicts that need to be solved.
- I think its the more natural way of working. You would say that the most natural way is using Database First. But remember that the database is just a tool to save your data. As a developer your point of view is your application. I dont care how its saved as long as my models are clear to read. I dont want to adjust my code to be able to save it in the database. The database should adapt to my code and that is exactly how Code First works.
- You have much more control over what is created and how things works. For example you can specify a character limit and a column size separately.
So I keep with the Code First approach (for now). If you still prefer the Model First or Database First approach you should try out this Free Data Access tool from Telerik! Its works like the Visual Designer in Visual Studio with some additional features. For example it can generate SQL migration scripts when changing a model. So instead of having to drop all database tables every time your change the name of a column this tool just generates a small SQL that will only affect the column name in that table.
Excelente post!
This is the best post about EF I have ever seen.
I don’t see how code first would handle a scenario where multiple appa access the same database administered by DBAs who have much more control over it.
Hi ! I’m about to create a project with Visual Studio, it’s an MVC web application with a huge database. Clients should be able to log into my web and see their information on the database. The data will be updated every week and I also want to save the different versions of it. The web page is only for showing information. Clients can’t modify it.
IDK if I should use code first or data first, which is better for this project?
And this is a great post by the way!!
Thank you so much for your answer!! 😀
PS: sry for my english, I’m spanish (:
very nice post
Ye and in advanced scenarios….. who wants code to maybe (?) drop indexes, constraints and triggers on db? code cant deal with that
Excellent post on the various options and its advantages and disadvantages. Thanks much for the wonderful article. I understand the developer mentality that a developer doesn’t have to care how the data is saved as long as the model is clear, but this can create a whole lot of problems when the application is really large and complex ( Of course this has a downside as well, later on you can have really nasty database scheme conflicts that need to be solved.). So I prefer flexibility and would prefer database first approach. Only correction I would recommend is you may want to change all “then” with “than”. I know its super silly and my apologies for that, but it threw me off a couple of times and I thought its beneficial for any future serious visitor.
Excellent. thanks
Extremely good… 🙂
The connection string is done in the main Web.Config instead of App.Config
Excellent post
Very nice article with descriptive explanation. Excellent Post.
Very good explanation, one of the best for confused beginners.
This post on EF is very helpful to have a clear idea on what approach to use in your project, and there by substantiate why we want to implement our application using that particular approach, Thanks to Roland Kierkels 🙂
Excellent article. Thanks
Very good ……………..
nice one brother,………….
“So instead of having to drop all database tables every time your change the name of a column this tool just generates a small SQL that will only affect the column name in that table.”
As a developer with a heavy SQL background… this makes me wonder about the article and the understanding of databases. I have never heard of any developer ever dropping all database tables whenever you change the name of a column…. ever. That’s what the “ALTER TABLE” syntax is for. Anyone that drops all tables to rename 1 column has absolutely no understanding of databases.
Having come from a background where DBAs look after the database and Devs look after the code, apps etc.
All the above methods make me shudder and can be dangerous. EF makes change a db too easy, which in some cases might be fine but in all the environments I have worked in the dbs are used in systems like a data warehouse, MI, reporting tools etc and not exclusive to a MVC web app. Changing of a db this way would give our DBAs kittens and could be catastrophic to the business !
Very nice post. Thank you!
Firs, thank you for this article. It does a nice job of explaining the three options in EF.
That being said, and based on over 20 years of SQL Server experience and 15 years of .NET experience and Microsoft certification in both, I concur with those above who think EF is a dangerous tool with great potential for doing damage to DBs and making it difficult to optimize DBs for best performance.